2026년 3월 30일 스탠퍼드와 MIT, 그리고 KRAFTON 연구진이 공동 발표한 <Meta-Harness: End-to-End Optimization of Model Harnesses> 논문입니다. (스탠퍼드의 이윤호, 크래프톤의 이광욱 두분의 한국분이!)
이 논문은 LLM 시스템의 성능을 결정짓는 핵심 요소인 하네스(Harness)를 에이전트가 스스로 설계하고 최적화하는 ‘Meta-Harness’ 시스템을 제안합니다. 여기서 하네스란 모델이 어떤 정보를 저장하고, 검색하며, 사용자에게 어떻게 제시할지를 결정하는 외부 코드 로직을 의미합니다.
기존의 하네스 설계는 주로 엔지니어가 수동으로 프롬프트를 다듬거나 로직을 수정하는 방식이었으나, Meta-Harness는 이를 ‘코딩 에이전트’가 주도하는 외부 루프(Outer-loop) 검색 체계로 전환했습니다.
이 시스템은 단순히 텍스트를 최적화하는 것을 넘어, 하네스를 구성하는 파이썬 코드 자체를 재작성하여 최적의 실행 절차를 찾아냅니다.
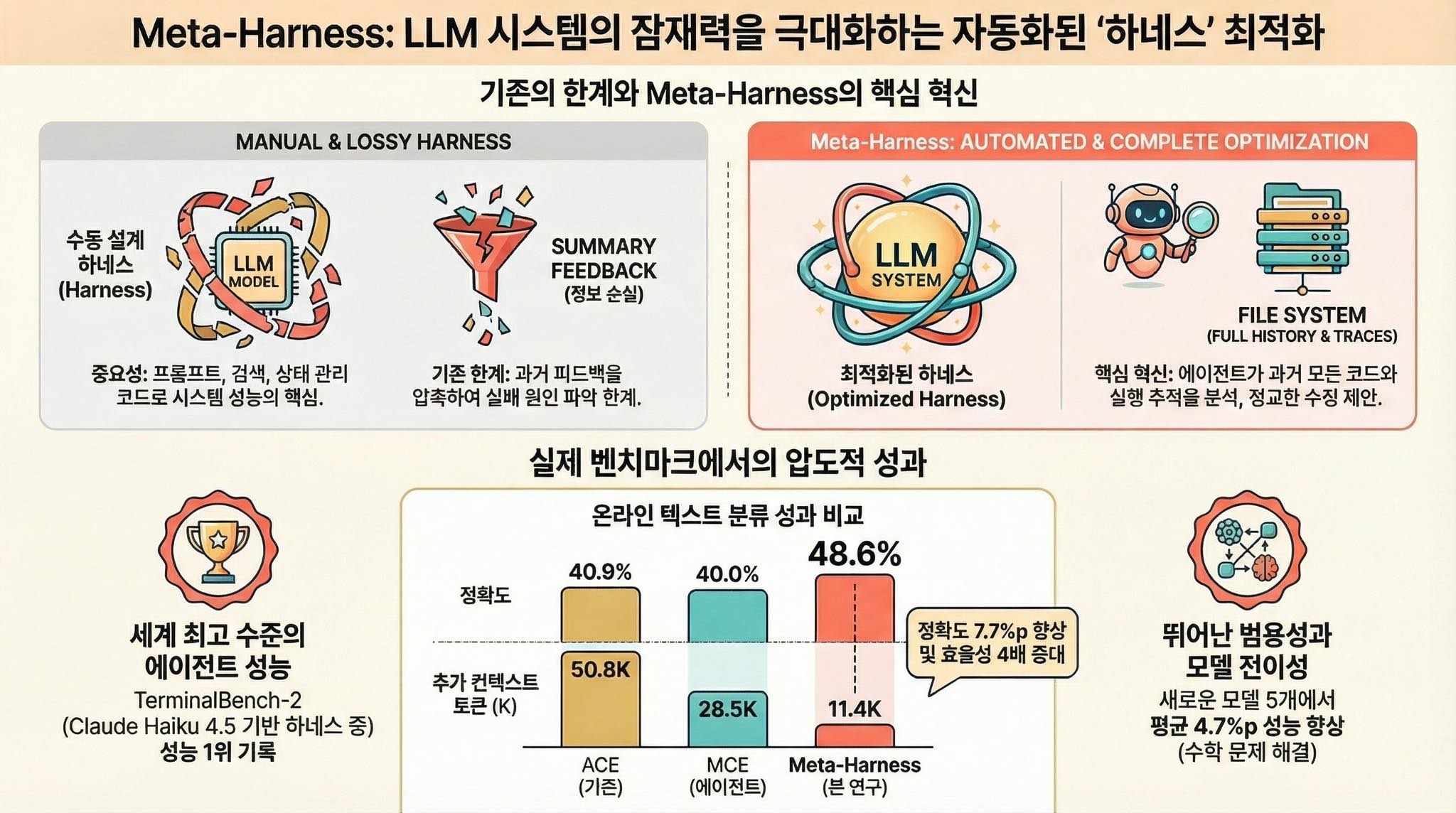
일반적인 하네스 스킬이나 텍스트 최적화 도구들과 Meta-Harness의 결정적인 차이는 ‘경험 데이터의 활용 방식’에 있습니다. 기존 방식은 이전 시도의 결과물을 짧은 요약이나 단순 점수로만 압축하여 에이전트에게 전달하기 때문에 정보의 손실이 큰데, Meta-Harness는 에이전트에게 과거의 모든 소스 코드, 실행 로그(Traces), 점수가 저장된 파일시스템 전체를 개방합니다.
에이전트는 수백만 토큰에 달하는 로그를 한 번에 읽는 대신, grep이나 cat 같은 터미널 도구를 사용하여 필요한 정보만 선택적으로 추출하는데, 에이전트가 숙련된 개발자처럼 파일시스템을 직접 탐색하며 문제를 진단하게 합니다.
단순히 무작위로 코드를 바꾸는 것이 아니라, 실패한 실행 로그를 분석하여 “특정 프롬프트 지침이 상태 정보를 유실시켰다”는 식의 가설을 세우고 이를 바탕으로 전략적인 수정을 제안합니다.
그리고, 프롬프트 문구만 수정하는 수준을 넘어, 검색 알고리즘이나 메모리 업데이트 로직 등 하네스의 알고리즘 구조 자체를 변경합니다.
그러니까, 클로드 코드에서 우리가 쓰는 하네스 스킬은 클로드라는 모델이 이미 학습을 통해 알고 있는 ‘팀 구성의 정석’을 바탕으로 자동화를 수행하는거고, 모델의 직관에 의존하는 방식이라면, Meta-Harness 는 모델의 직관에만 의존하지 않고, 대신 파일시스템에 기록된 과거의 모든 시도, 즉 어떤 코드를 짰고 어떤 로그가 남았으며 점수가 몇 점이었는지를 전부 뒤져봅니다. 즉, “어제는 이렇게 팀을 짰더니 여기서 막혔네?”라는 실시간 데이터를 보고 다음 전략을 수정하는 방식인거 같습니다.
온라인 텍스트 분류에서 기존 최강자인 ACE 대비 7.7점의 정확도 향상을 기록하면서도 컨텍스트 토큰은 4배나 덜 사용하는 극강의 효율을 증명했고, 또한, 경쟁이 치열한 TerminalBench-2에서 수동 설계된 최정상급 에이전트들을 제치고 1, 2위를 다투는 성과를 냈습니다.
특정 모델로 만들어진 하네스 전략이 학습되지 않은 다른 5개의 모델(Gemini, GPT 등)에서도 평균 4.7점의 성능 향상을 이끌어냈습니다. 하네스가 모델의 한계를 보완하는 ‘범용적 문제 해결 전략’임을 시사합니다. 블랙박스인 모델 내부를 건드리는 대신, 사람이 읽을 수 있는 코드인 하네스를 최적화하므로 결과물에 대한 검증과 디버깅이 훨씬 용이합니다.
정리하자면, Meta-Harness는 에이전트에게 풍부한 원시 로그 데이터와 자유로운 파일 탐색 도구를 주었을 때, 스스로 사람을 능가하는 시스템 설계자가 될 수 있음을 증명했습니다. 모델 튜닝보다 하네스 자동화가 훨씬 경제적이고 강력한 수단이 될 수 있다는 말입니다.