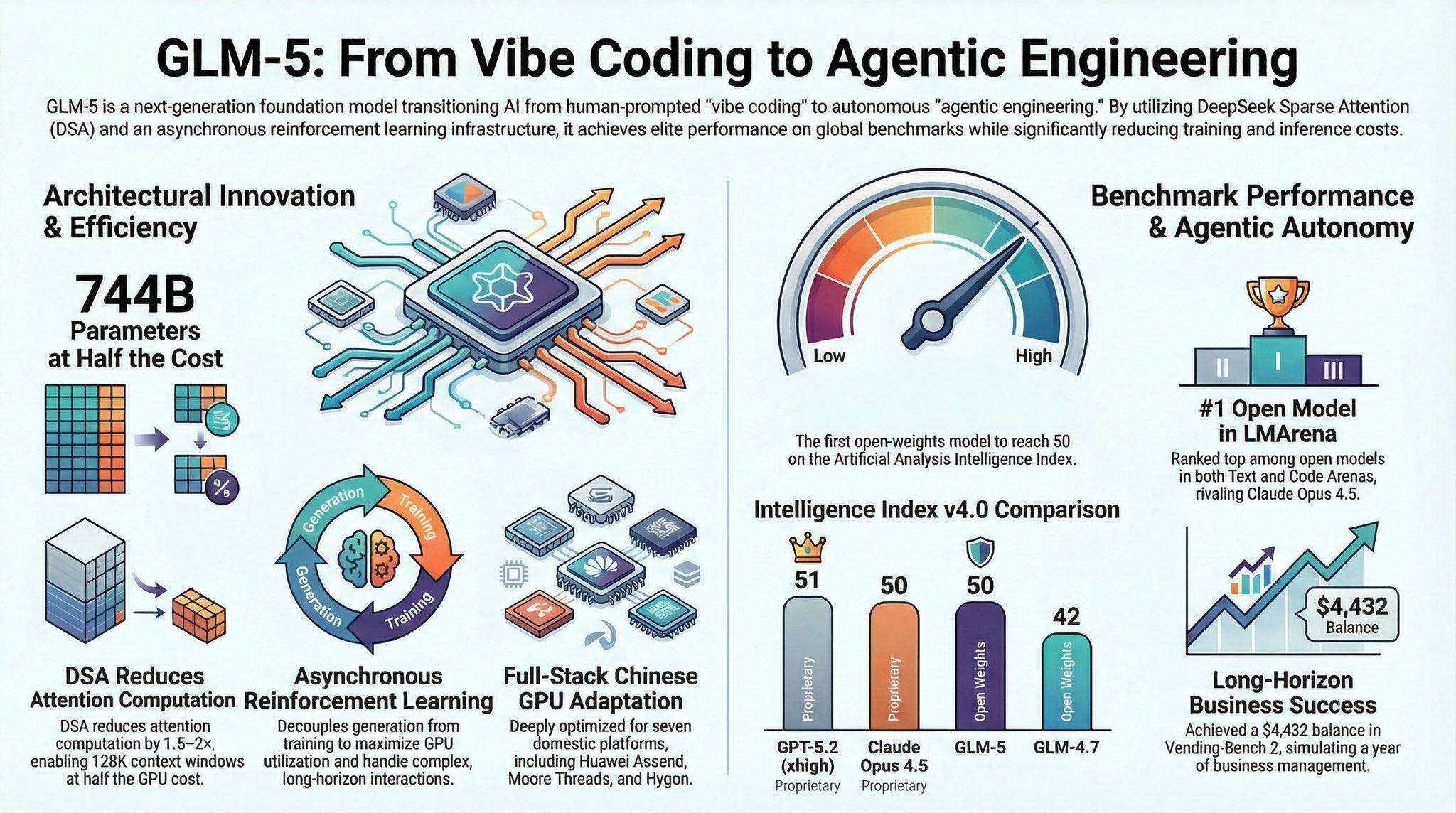
GLM-5 테크리포트가 2월 17일에 올라왔네요. 이 테크리포트는 제목 <GLM-5: from Vibe Coding to Agentic Engineering> 처럼, AI가 단순히 인간의 프롬프트로 코드 조각을 짜주던 수동적인 바이브 코딩(Vibe Coding) 시대에서, AI 스스로 전체 소프트웨어 개발 과정을 기획, 구현, 검증, 수정하는 주도적인 에이전트 기반 엔지니어링(Agentic Engineering)시대로의 전환을 제시하고 있습니다.
이를 위해 비용은 확 줄이면서 긴 문맥을 이해하는 고효율 아키텍처(DSA)와 AI의 장기적인 자율 작업을 가능케 하는 혁신적인 훈련법(비동기식 강화학습)을 도입했으며, 무엇보다 중국 자체 AI 칩 생태계에 완벽히 최적화하여 기술 자립과 성능이라는 두 마리 토끼를 모두 잡은 차세대 파운데이션 모델을 설명합니다.
좀더 자세히 정리해보면,
1. 바이브 코딩’에서 ‘에이전트 기반 엔지니어링’으로
이 논문을 관통하는 가장 중요한 철학은 AI가 소프트웨어를 다루는 방식의 근본적인 진화입니다.
– 바이브 코딩(Vibe Coding)의 한계: 기존의 방식은 인간 사용자가 프롬프트를 입력하면 AI 모델이 이에 맞춰 코드를 작성해 주는 수동적인 형태였습니다. 이는 본질적으로 단일 턴(Single-turn) 기반의 고립된 코드 생성에 머무르며, 코드베이스의 전체적인 맥락이나 장기적인 상태 변화를 추적하지 못하는 한계를 지닙니다.
– 에이전트 기반 엔지니어링(Agentic Engineering)의 도래: 반면, GLM-5가 지향하는 새로운 패러다임에서는 AI 에이전트가 직접 코드를 작성할 뿐만 아니라, 스스로 계획(plan)을 수립하고, 구현(implement)하며, 그 결과를 바탕으로 반복 개선(iterate)하는 자율성을 갖습니다.
이러한 자율적 엔지니어링을 위해 AI는 Large Repo Exploration 을 통해 방대하고 낯선 코드베이스에서 목표 파일을 전략적으로 찾아내야 합니다.
또한, 한 단계의 작업이 다음 작업의 맥락을 변화시키는 Multi-step Chained Tasks을 수행하며 장기적인 맥락 유지와 점진적 개발 능력을 증명해야 합니다.
2. 고효율 아키텍처와 대규모 사전 학습
이러한 고도의 자율성을 구현하기 위해 GLM-5는 기초 체력부터 혁신적으로 재설계되었습니다.
– 효율적인 파라미터 스케일링: GLM-5는 총 7,440억 개(744B)의 파라미터를 가진 전문가 혼합(MoE) 모델로 스케일업 되었으나, 실제 활성화되는 파라미터는 400억 개(40B)로 억제하여 통신 오버헤드를 최소화했습니다.
– DSA(DeepSeek Sparse Attention)의 도입: 특히 주목할 점은 DSA 아키텍처를 도입하여 훈련 및 추론 비용을 대폭 절감하면서도 긴 컨텍스트(Long-context)에 대한 이해도를 높게 유지했다는 것입니다. 이를 통해 최대 20만(200K) 토큰에 달하는 방대한 문맥을 안정적으로 처리할 수 있게 되었습니다.
– 다중 토큰 예측(MTP): 또한, 파라미터 공유를 통한 다중 토큰 예측(Multi-token Prediction) 기술을 적용하여 훈련 시 메모리 부담을 기존과 동일하게 유지하면서도 추론 속도와 수용률(acceptance rate)을 향상시켰습니다.
3. 비동기식 강화학습(Asynchronous RL) 인프라
에이전트 기반 엔지니어링을 가능하게 한 결정적 기술은 모델 정렬 및 포스트 트레이닝(Post-training) 단계에 적용된 새로운 강화학습 인프라입니다.
– 비동기식 RL 및 훈련-추론 분리: 에이전트가 수 시간 동안 코드를 작성하고 환경과 상호작용하는 긴 궤적(long-horizon)의 롤아웃 과정에서는 심각한 GPU 유휴 시간(병목 현상)이 발생합니다. 이를 해결하기 위해 GLM-5 연구진은 중앙 오케스트레이터를 통해 훈련 엔진과 추론 엔진을 완전히 분리하는 비동기식 RL 프레임워크를 개발하여 GPU 활용도와 훈련 효율을 극대화했습니다.
– TITO(Token-in-Token-out) 게이트웨이: 비동기 훈련의 안정성을 위해, 추론 엔진에서 생성된 토큰을 텍스트로 변환하지 않고 토큰 ID 그대로 훈련 파이프라인에 직접 전달하는 TITO 방식을 도입했습니다. 이는 재토큰화(re-tokenization)로 인한 경계 불일치나 정보 손실을 원천 차단하여 오프폴리시(off-policy) 환경에서도 안정적인 학습을 보장합니다.
– 다차원 일반 강화학습: 모델의 전반적인 품질을 높이기 위해 ‘근본적 정확성(사실적 오류 및 지시 불이행 최소화)’, ‘감성 지능(자연스럽고 공감하는 소통)’, ‘작업 특화 품질’이라는 세 가지 차원으로 목표를 세분화하여 최적화했습니다.
4. 에이전트 검증 : CC-Bench-V2와 Agent-as-a-Judge
정적인 벤치마크 점수를 넘어, 현실의 엔지니어링 환경에서 에이전트가 얼마나 잘 작동하는지 검증하기 위해 내부 평가 지표인 CC-Bench-V2를 도입했습니다.
– 자율 심사 에이전트(Agent-as-a-Judge): 프론트엔드 작업의 경우, 코드가 빌드되는지 확인하는 정적 분석을 넘어, GUI 에이전트(Playwright 도구 및 멀티모달 LM 탑재)가 실제 배포된 UI를 클릭하고 상호작용하며 시각적/기능적 결함을 찾아내는 혁신적인 자율 심사 시스템을 구축했습니다.
– 장기 궤적(Long-horizon) 및 비즈니스 시나리오: 가상의 자판기 사업을 1년간 운영하며 자원을 관리하는 Vending-Bench 2 테스트에서 GLM-5는 최종 4,432달러의 잔고를 기록하며 오픈소스 모델 중 1위를 달성했습니다.
5. 기술 자립 생태계 구축과 ‘Pony Alpha’의 성공
마지막으로, 이 모델은 기술적 완성도뿐만 아니라 하드웨어 생태계에서 중국자립을 이뤄냈습니다.
– 중국 자체 칩 풀스택 최적화: 기획 초기부터 화웨이 어센드(Ascend)를 비롯한 7개의 주요 중국 자체 칩 플랫폼에 맞게 W4A8 혼합 정밀도 양자화와 특화된 퓨전 커널(Lightning Indexer 등)을 적용해 효율성을 극대화했습니다.
– Pony Alpha 블라인드 테스트: 연구진은 브랜드 후광 효과나 지정학적 편견을 배제하기 위해, 정식 발표 전 OpenRouter에 ‘Pony Alpha’라는 가명으로 모델을 배포했습니다. 사용자들은 그 압도적인 코딩 및 에이전트 성능에 놀라 Claude Sonnet 5나 DeepSeek V4로 착각했고, GLM-5의 실질적인 경쟁력을 가장 객관적으로 증명한 사건이 되었다고 하네요.
자 간단히 정리하면, GLM-5는 대규모 연산 자원에 의존하던 기존의 수동적 언어 모델(LLM)에서 벗어나, 고효율 아키텍처와 고도의 비동기식 강화학습 인프라를 바탕으로 능동적이고 독립적인 문제 해결 능력을 갖춘 진정한 의미의 ‘AI 엔지니어’ 인겁니다.
이번 GLM-5가 증명한 ‘에이전트 기반 엔지니어링’으로의 패러다임 전환은 단순한 프롬프트를 넘어 장기적인 작업 맥락과 기억을 바탕으로 자율적인 기획 및 검증을 수행하는 LMM(Large Memory Model)으로의 진화가 본격화되었음을 보여주는 명확한 기술적 변곡점이라고 생각합니다.
나아가 이러한 고도의 자율형 에이전트 역량이 OpenClaw와 같은 프레임워크를 통해 개인의 로컬 PC 환경에 온전히 안착하게 된다면, 궁극적으로는 중앙 집중형 시스템에 의존하지 않고 점점더 개별 로컬 에이전트들이 독립적으로 사고하며 상호작용하는 거대한 사회적 모델(LSM, Large Social Model) 생태계로 도약하는 강력한 촉매제가 될 것 같습니다.
OpenClaw와 같은 로컬 프레임워크의 가장 큰 한계는 탑재되는 오픈소스 모델의 추론 및 계획 능력이 부족하다는 점이었는데,GLM-5는 폐쇄형 상용 모델(Claude Opus 4.5 등)에 필적하는 자율적인 에이전트 엔지니어링 능력을 오픈웨이트로 달성했죠. 게다가 개별 에이전트들이 소통하는 LSM 생태계가 구축되려면 개별 에이전트 구동 비용이 저렴해야 하는데, GLM-5는 DSA 와 4비트 양자화(INT4)를 통해 연산 비용을 극단적으로 낮추었습니다. 총 7,440억 개의 파라미터(활성 400억 개)를 가진 거대 모델임에도 불구하고 중국의 단일 칩 노드에서 구동이 가능해져서, GLM-5가 증명한 에이전트 훈련 방법론(TITO, 비동기식 RL 등)과 DSA 는 곧바로 로컬 PC에서 구동 가능한 소형 파운데이션 모델(8B~30B 급)로 빠르게 이식될 것으로 예상할 수 있기 때문입니다.
에이전트가 점점 더 보조자에서 주인공이 되고 있습니다.