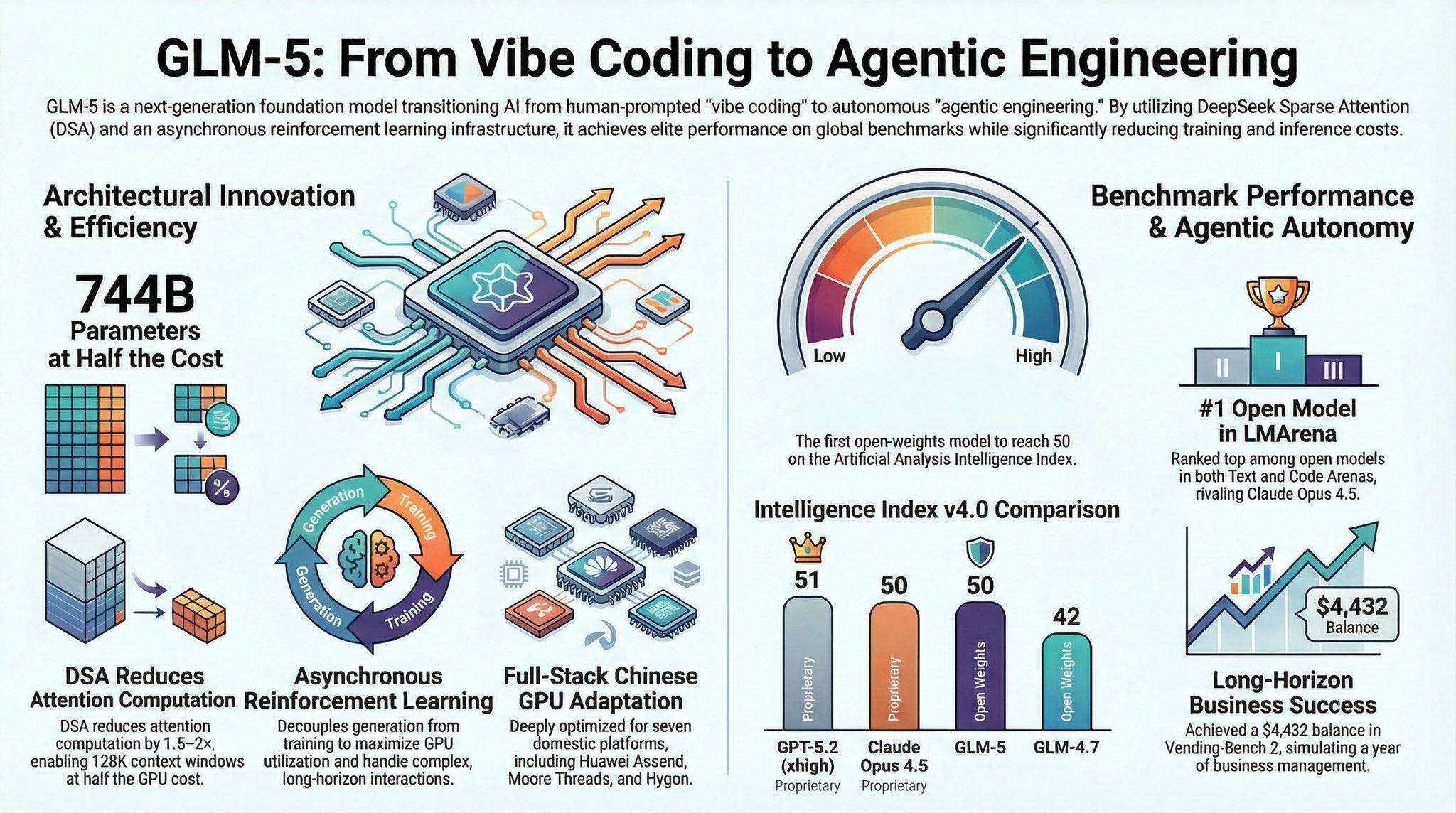
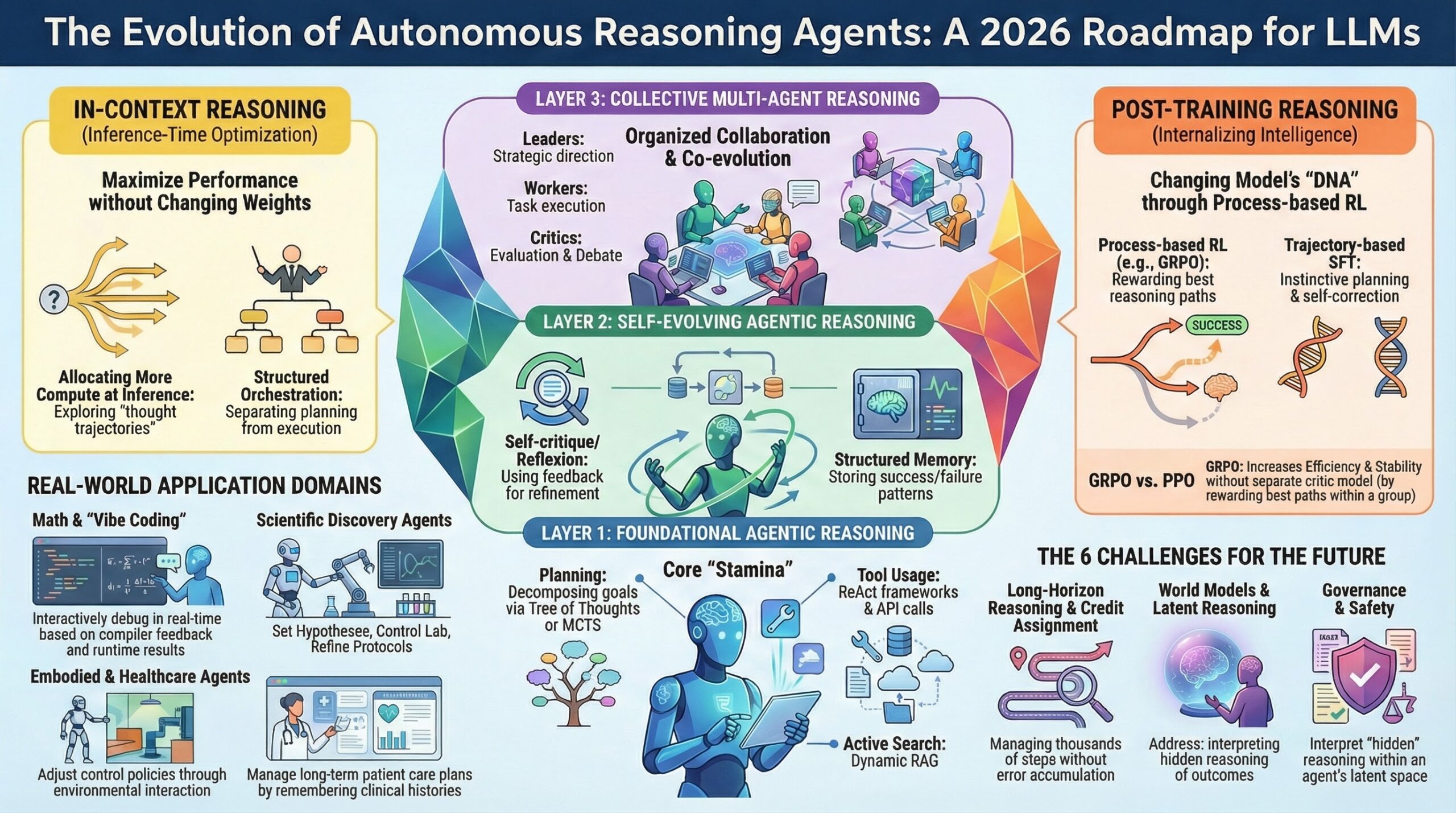
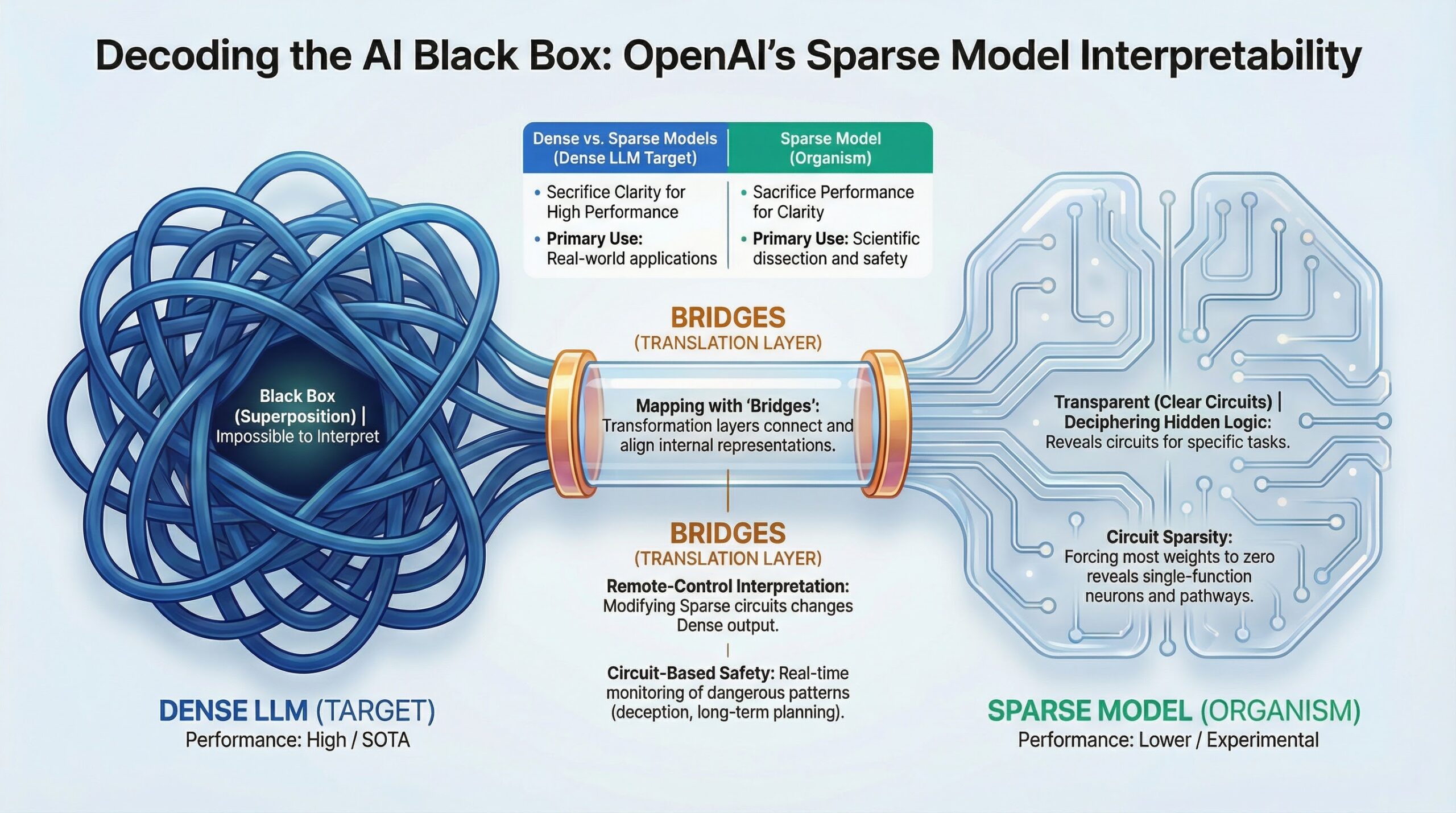
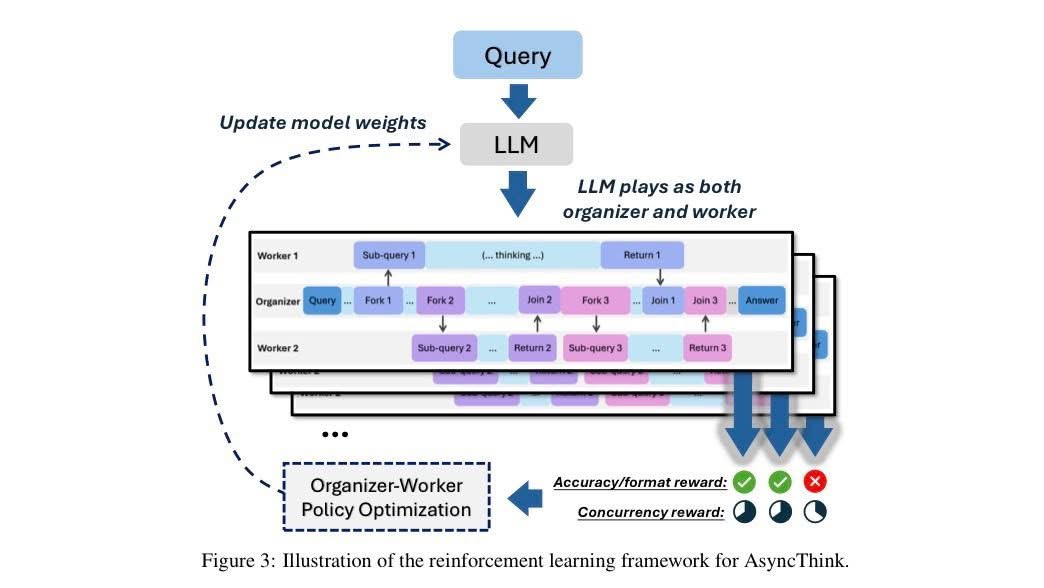
훈련없는 학습 (Learning without Training)
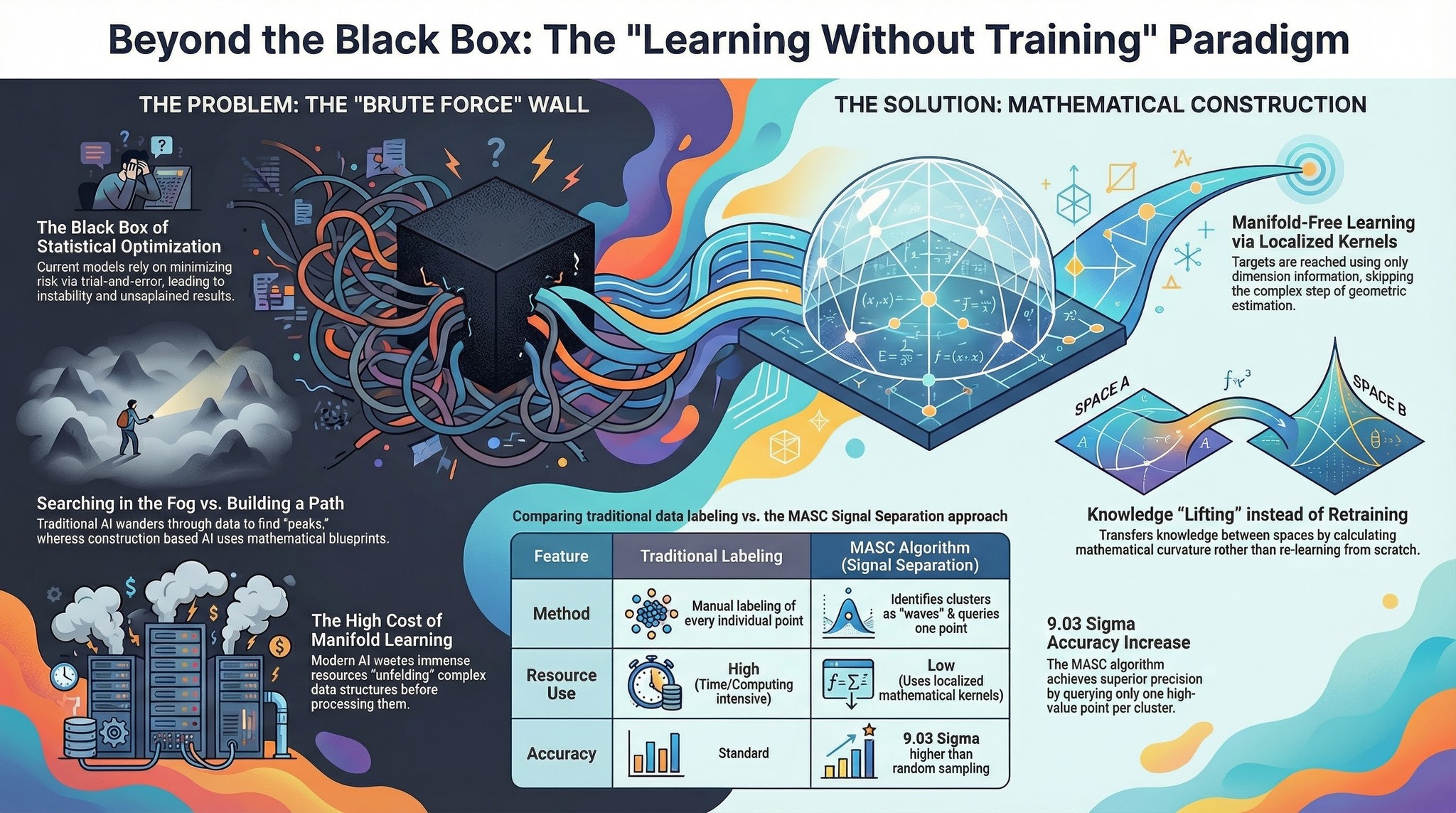
오늘날의 머신러닝, 특히 딥러닝 모델은 본질적으로 방대한 데이터를 바탕으로 한 통계적 최적화 과정에 크게 의존하고 있습니다. Empirical Risk 를 최소화하기 위해 경사 하강법같은 훈련 방식을 사용하지만, 그러다보니 Local minimum 에 빠지거나 수렴이 느려지는 등 태생적인 불안정성을 안고 있습니다. 그러다보니 이러한 최적화 기반 훈련은 결과의 도출 과정을 설명하기 어려운 ‘블랙박스’ 문제를 야기시키 기도 합니다. 수학자 라이언 … 더 읽기