“AI는 이제 단순한 소프트웨어가 아니라 전략 자산이 되었고, 그 능력을 대규모로 빼내는 시도가 실제로 벌어지고 있다”
2월 23일 Anthropic은 자사 모델 Claude를 대상으로 조직적이고 대규모적인 증류(distillation) 시도가 탐지되었다고 밝혔습니다. 증류는 원래 합법적인 머신러닝 기법으로, 큰 모델(teacher)의 출력 결과를 활용해 더 작은 모델(student)을 훈련시키는 방식입니다. 내부적으로 경량 모델을 만들거나 비용을 줄이는 데 자주 쓰이죠.
문제는 허가 없이, 경쟁 모델 강화를 위해, 대규모 자동화 계정을 통해 수행되었을 때입니다. Anthropic은 이를 “distillation attack”이라고 규정합니다.
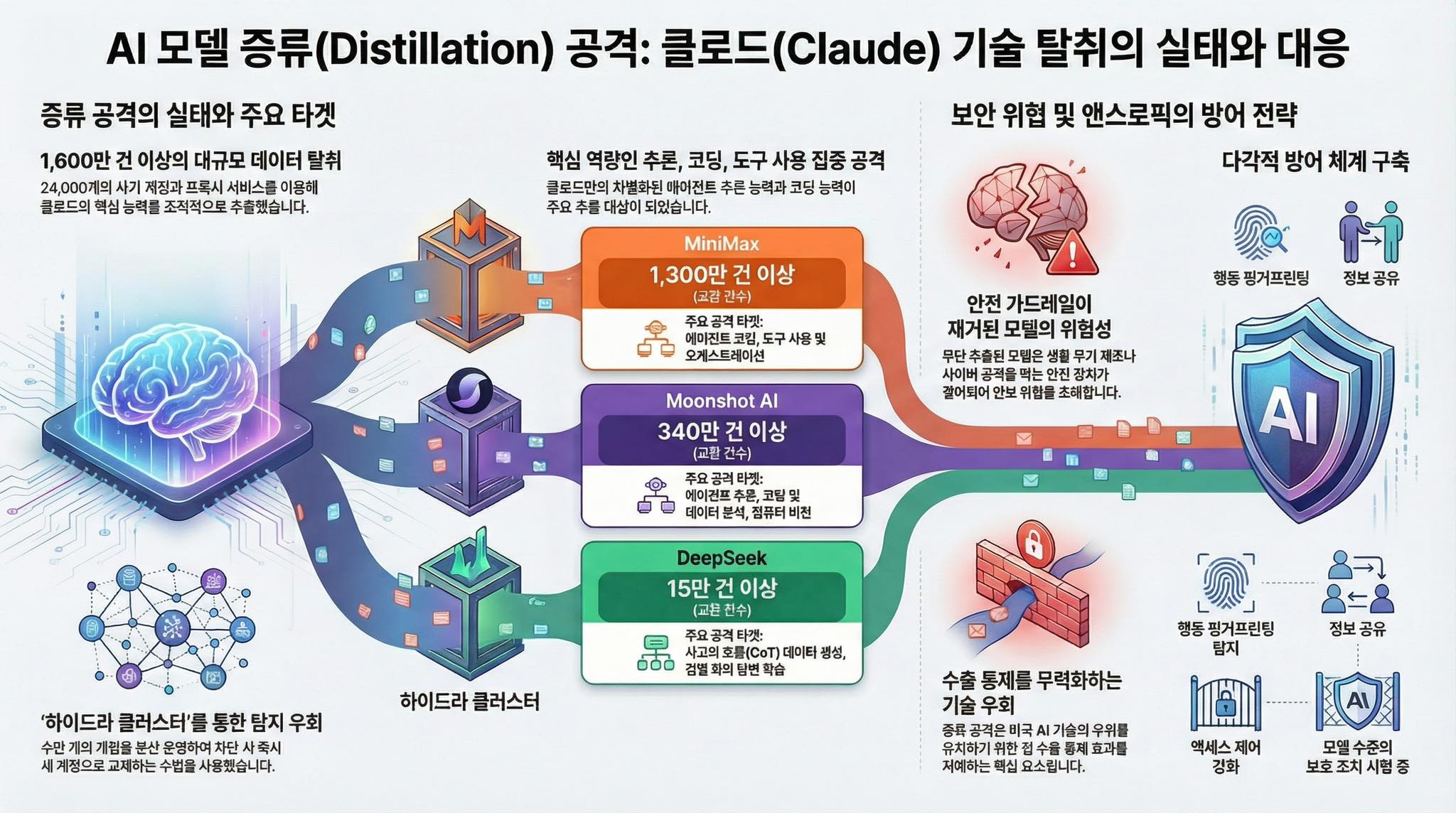
앤트로픽이 밝힌 정황에 따르면 DeepSeek, Moonshot, MiniMax 에서 약 24,000개의 가짜 계정을 통해 Claude와 1,600만 건 이상의 상호작용을 생성하면서 추출, 복제하려고 했다고 합니다.
패턴은 인간 사용자라기보다는, 특정 형식의 질문을 반복적으로 던지고 응답을 체계적으로 수집하는 자동화 트래픽이었고, 일반 사용자 행태와는 통계적으로 구별되는 특징을 보였다고 설명합니다.
# 사례
DeepSeek
– DeepSeek은 상대적으로 적은 수의 상호작용(수십만 건)을 수행했지만, 기초 논리 추론 능력과 정책 민감 질문에 대한 대응, 그리고 검열 회피형 리라이트(문장 변환) 같은 Claude만의 특정 능력을 캡처하는 데 집중했다는 분석입니다.
Moonshot AI
– Moonshot은 Agent-type reasoning(자율적 문제 해결), 도구 활용 능력, 코딩/데이터 분석 등 다양한 고급 기능을 대상으로 수백만 건의 상호작용을 한 것으로 Anthropic은 파악했습니다. Moonshot의 자체 소형 모델들에 모두 적용되었다고 언급됩니다. 
MiniMax
– MiniMax는 세 그룹 중 가장 큰 규모(1,300만 건 이상)로 Claude와 상호작용한 것으로 보입니다. 목표는 반응적 코딩 능력과 툴 오케스트레이션(외부 기능과 연동해 복잡한 작업 처리) 같은 고급 기능을 포착하는 것이었습니다. Anthropic은 MiniMax 캠페인을 진행 중에 탐지했다고 밝혔고, 새로운 Claude 모델이 출시되자마자 약 24시간 이내에 해당 모델로 트래픽의 절반을 전환하는 신속한 전략 변경을 관찰했다고 합니다.
Anthropic이 특히 강조하는 것은 두 가지입니다.
첫째는 안전 문제입니다. Claude는 내부적으로 안전장치와 거버넌스 필터를 포함하고 있지만, 출력만 수집해 재학습한 모델은 그런 안전 체계를 그대로 복제하지 못할 가능성이 높다는 겁니다. 결과적으로 “능력은 있지만 통제력이 약한” 모델이 탄생할 수 있다는 우려입니다. 단순한 상업적 손해를 넘어, 생물학·사이버·군사 영역에서 악용될 위험까지 연결된다고 주장합니다.
둘째는 지정학적 함의입니다. 미국의 AI 및 반도체 수출 통제는 첨단 모델 개발을 전략적으로 관리하려는(특히, 중국..)정책적 장치입니다. 고성능 모델을 API 형태로 접속해 출력만 수집해도 상당한 능력을 복제할 수 있다면, 이러한 통제는 우회될 수 있죠. GPU없이 컴퓨팅을 하는거니까요. Anthropic은 이 지점을 “국가안보적 문제”로 framing합니다. AI 모델은 국가전략자산인 셈이죠.
이에 대한 대응으로 Anthropic은 다층적 방어 전략을 제시합니다.
비정상적 요청 패턴을 탐지하는 분류기, 다계정 행동 분석, 접근 통제 강화, 업계 간 위협 정보 공유, 그리고 모델 출력 자체를 구조적으로 조정해 무단 학습에 덜 유용하게 만드는 기술적 대응 등입니다. 단순히 계정을 차단하는 수준이 아니라, 장기적으로는 모델 능력 보호를 하나의 보안 영역으로 다루겠다는 것으로 보입니다.
중국……. 다이나믹합니다.
* 출처 : https://www.anthropic.com/…/detecting-and-preventing…